



Research
My current work supports the Scale AI effort under the Microelectronics Commons program, focused on 3D chip design execution and system measurement & verification for large-scale “Illusion” multi-chiplet designs.
Previously, I built CMOS/FPGA systems for probabilistic computing with p-bits (Ising/Boltzmann machines) and distributed architectures for fast sampling, learning, and quantum-inspired optimization.
Previously, I built CMOS/FPGA systems for probabilistic computing with p-bits (Ising/Boltzmann machines) and distributed architectures for fast sampling, learning, and quantum-inspired optimization.
Research areas
3D multi-chip systems & verification
- 3D chip design execution and integration workflows
- System measurement & validation of silicon/prototypes
- Verification strategies for large “Illusion” multi-chiplet systems
Robust system measurement & bring-up
- End-to-end measurement planning (test hooks → metrics)
- Debug workflows spanning RTL/emulation to lab instruments
- Scaling-aware validation: corner cases, failure modes, and observability
Probabilistic computing (prior work)
- p-bit based Ising/Boltzmann machines on CMOS/FPGA
- Distributed, latency-tolerant fabrics for extreme-scale sampling
- Applications: optimization, energy-based ML, AI sampling
Full-stack focus
Silicon / system layer
- 3D integration constraints: testability, observability, bring-up
- Measurement-driven iteration loops (hardware ↔ models)
- Robustness: fault isolation and scaling bottlenecks
Architecture
- Multi-chiplet partitioning and communication-aware design
- Verification-friendly interfaces and debug visibility
- Distributed probabilistic fabrics: async, delay-tolerant links (prior)
Algorithms / workflows
- Validation workflows across abstraction levels
- Performance/robustness characterization with system-level metrics
- SA/PT/ICM/SQA and hardware-aware learning loops (prior)
Selected figures of merit (prior p-computer work)
1500B flips/s (measured) Up to 6 orders vs. CPU Gibbs ≈100× vs. GPU/TPU (flips/s & energy) 6-FPGA UCSB: ~50k p-bits (async links) Synthesized 1M p-bits on 18× VP1902 (Siemens) 4,264 p-bits / ≈30k params (DBM)
Spotlight (selected prior work)
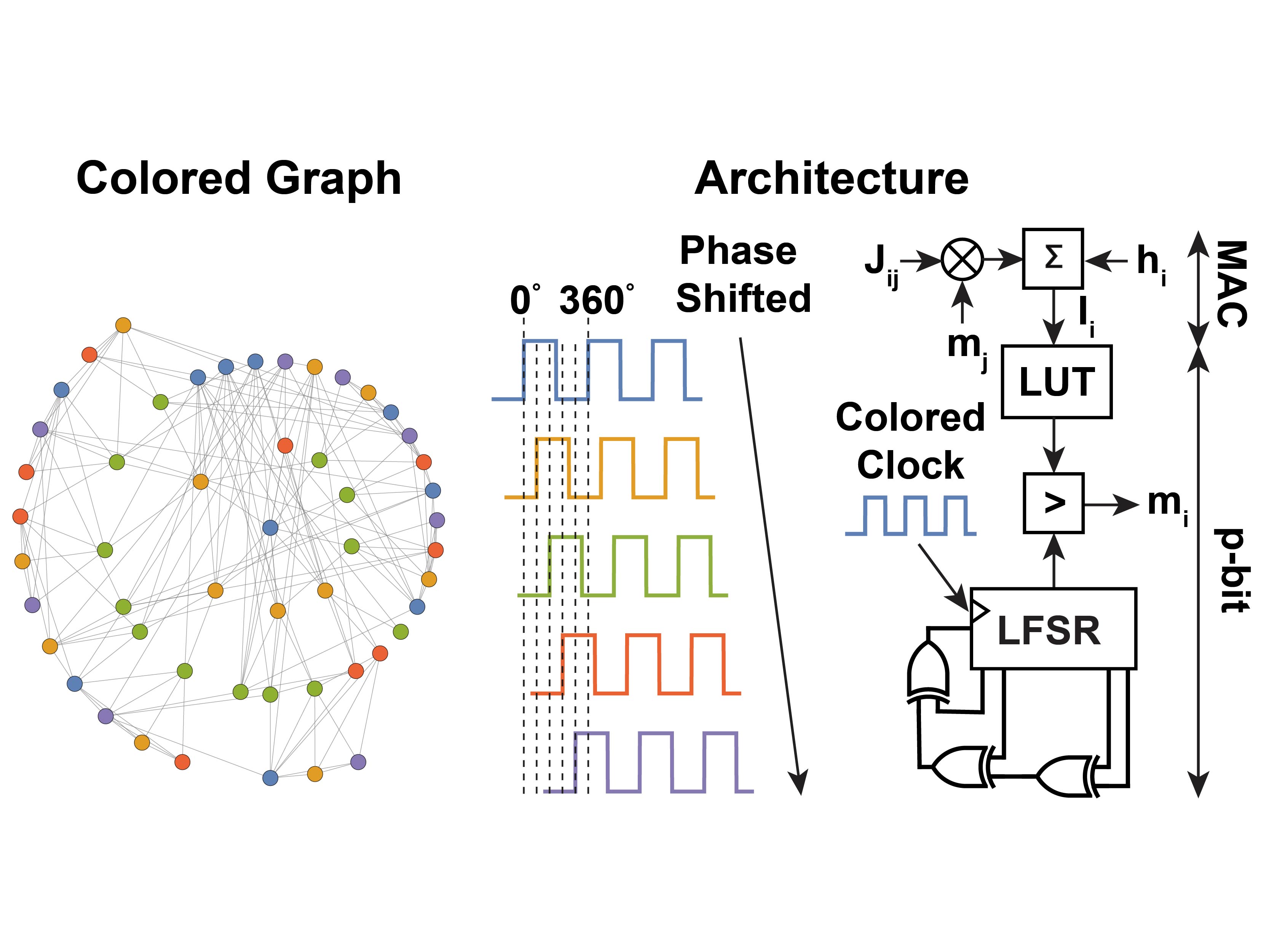
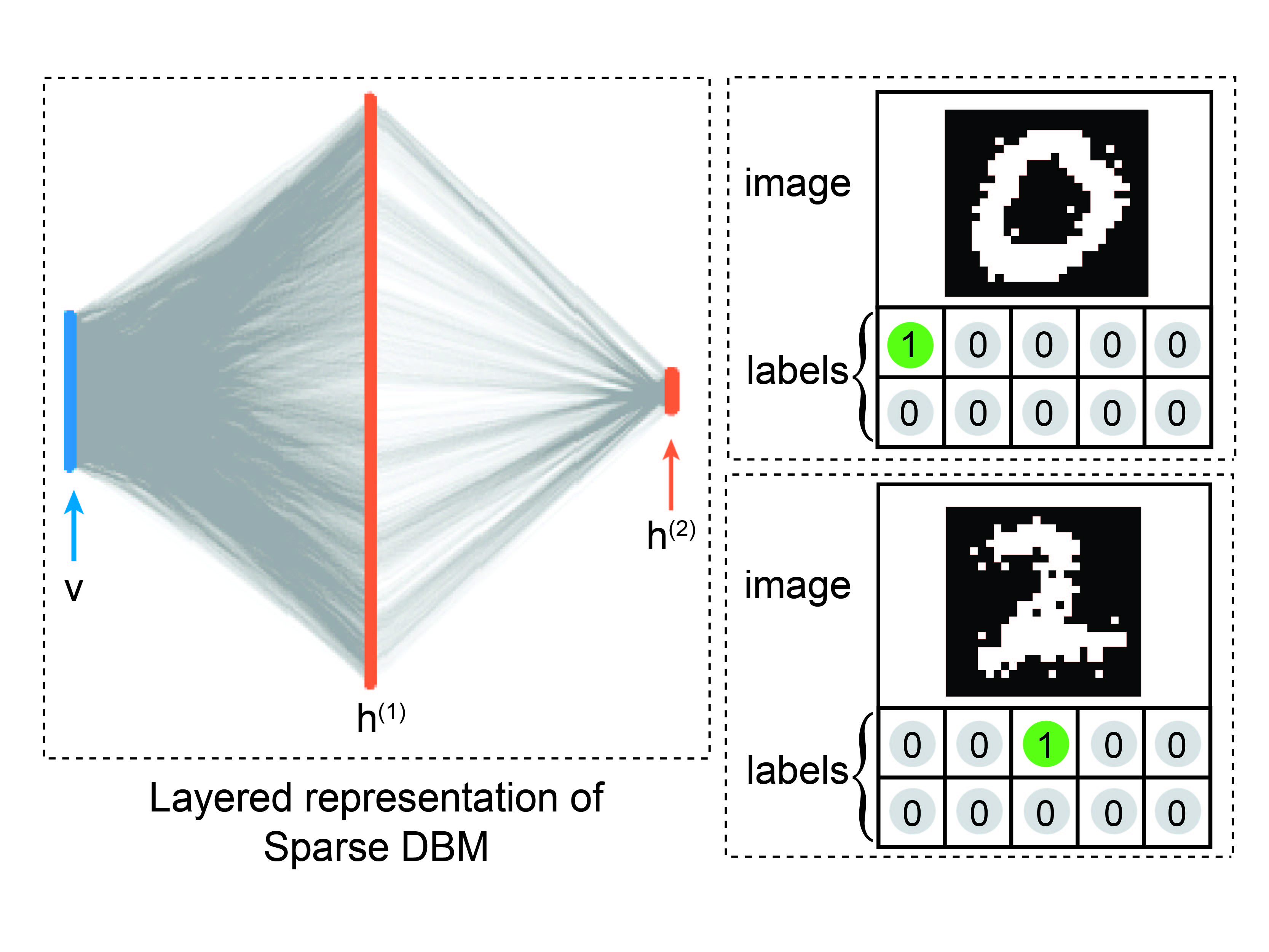
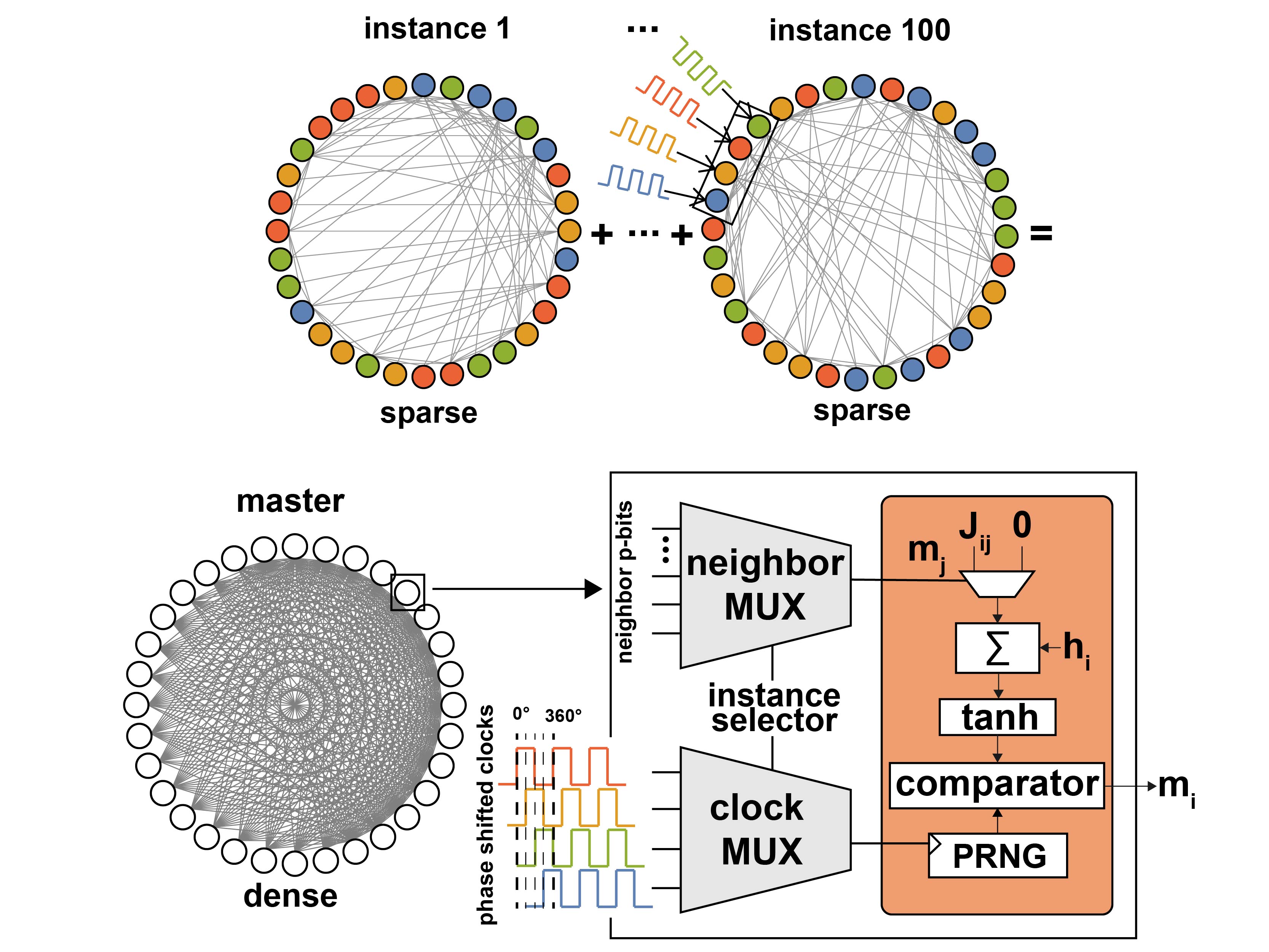

Methods I use
- 3D chip integration workflows
- System measurement & characterization
- Hardware validation & debug (RTL → system)
- Massively parallel (graph-colored) Gibbs
- Simulated Annealing (SA)
- Adaptive Parallel Tempering (APT)
- Simulated Quantum Annealing (SQA)
- Isoenergetic Cluster Moves (ICM)
- Non-equilibrium Monte Carlo (NMC)
- Higher-order p-bits / couplers
- DBM training (hardware-aware)
- NQS sampling & training
Current directions
- 3D chips & multi-chiplet verification: design execution plus system measurement/verification for large-scale “Illusion” multi-chiplet systems.
- Robust, scalable measurement: validation workflows that remain effective as systems scale in complexity and integration density.
- Cross-layer co-design: interfaces and architectures shaped by what is measurable, verifiable, and debuggable in real hardware.
Full publication list: Publications